C# 13
La nueva versión de C# 13 salida recientemente, que estará disponible en .NET 9, disponible en la versión más actualizada de Visual studio 2022. Esta versión incluirá una serie de características que estarán disponibles en la página de novedades de #13 (Novedades de C#), por el momento están en versión preliminar y no disponibles oficialmente.
Novedades importantes publicadas actualmente.
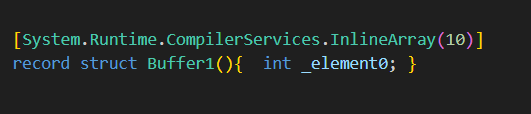
Atributo InlineArray en estructuras record no estará disponible.
El atributo InlineArray en C# es una característica utilizada para optimizar el almacenamiento de matrices (arrays) pequeñas en la pila en lugar de en el heap, mejorando así el rendimiento. Este atributo permite definir un campo como un array in-line, es decir, que se almacena directamente dentro de la estructura en lugar de ser una referencia a una ubicación separada en el heap. La combinación de InlineArray con los registros de estructuras nos permite obtener los beneficios de ambas en conjunto.
En esta versión pasará a retirarse esta estructura:
Mostrará la siguiente alerta:
Error CS9259: Attribute ‘System.Runtime.CompilerServices.InlineArray’ cannot be applied to a record struct.
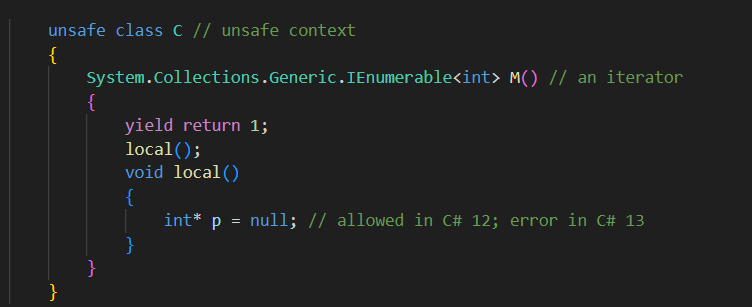
Los iteradores introducen un contexto seguro en C# 13 y versiones posteriores. Lo que significa que el comportamiento predeterminado será como si estuviera en un contexto seguro, permitiéndonos en caso de no desearlo indicarlo explícitamente que no deseamos este comportamiento.
Otras características anunciadas
Nueva secuencia de escape: puede usar \e como una secuencia de escape literal de caracteres para el carácter de ESCAPE (U+001B en unicode). Anteriormente, se usaba \u001b o \x1b.
Tipos naturales de grupo de métodos: Esta característica realiza pequeñas optimizaciones para solucionar sobrecargas con grupos de métodos. Lo que proporciona:
- Mejor Eficiencia: Al reducir el conjunto de métodos candidatos a considerar, mejora el rendimiento del compilador y reduce el tiempo de compilación.
- Claridad y Mantenimiento: Proceso de resolución más claro y fácil de entender, facilitando la depuración y el mantenimiento del código.
- Predictibilidad y Consistencia: Resultados de la resolución de sobrecargas más consistentes y predecibles, aumentando la confiabilidad del compilador.
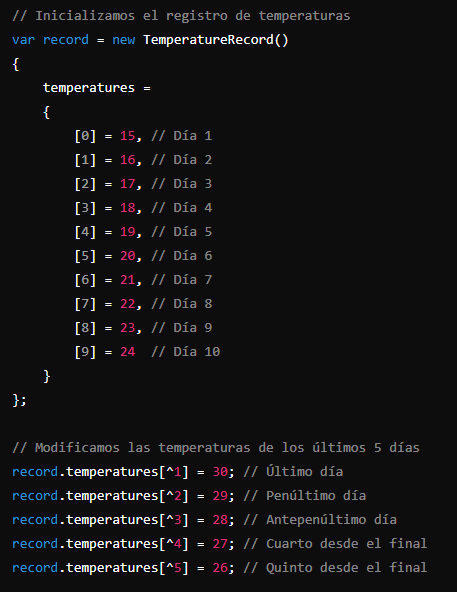
Acceso a índices implícitos:
En C# 13, se introduce la capacidad de usar el operador de índice implícito “from the end” (^) en inicializadores de objetos. Esto permite acceder a los elementos de una colección o matriz desde el final en lugar de desde el principio, lo cual no era posible en versiones anteriores.
Esta característica es especialmente útil cuando se trabaja con colecciones donde solo se necesitan modificar los últimos elementos, proporcionando una sintaxis más directa y menos propensa a errores.
Características que podríamos esperar(No todas anunciadas oficialmente):
Escape character
- Mejora en el manejo de caracteres de escape.
Method group natural type improvements
- Mejora en la tipificación natural de grupos de métodos.
Lock object
- Mejoras en el manejo de objetos de bloqueo (lock).
Implicit indexer access in object initializers
- Acceso implícito a indexadores en inicializadores de objetos.
Params-collections
- Soporte para colecciones en parámetros (params).
Ref/unsafe in iterators/async
- Permite código no seguro (unsafe) y referencias (ref) en iteradores y métodos asincrónicos.
Allows ref struct constraint
- Permite restricciones de ref struct en interfaces.
Overload Resolution Priority
- Mejoras en la prioridad de resolución de sobrecargas.
Partial properties
- Soporte para propiedades parciales.
.NET 9
La nueva versión de .NET 9, sucede a la versión .NET8, con un enfoque basado en el rendimiento y las aplicaciones nativas en la nube.
Podemos ver que para la versión preview 2, se ven algunos cambios el las bibliotecas principales .NET.
Estos serán los siguientes puntos mas relevantes que se verán actualizados::
- Serialización
- LINQ
- Colecciones
- Criptografía
- Reflexión
- Rendimiento
- Pruebas unitarias
Serialización
La biblioteca System.Text.Json incorpora nuevas opciones y un nuevo singleton que facilita la serialización.
Opciones de sangría
JsonSerializerOptions permiten personalizar el carácter y el tamaño de sangría del json.
Opciones web predeterminadas
El nuevo singleton JsonSerializerOptions.Web permite serializar de la forma que lo hacer ASP.NET Core para aplicaciones web.
LINQ
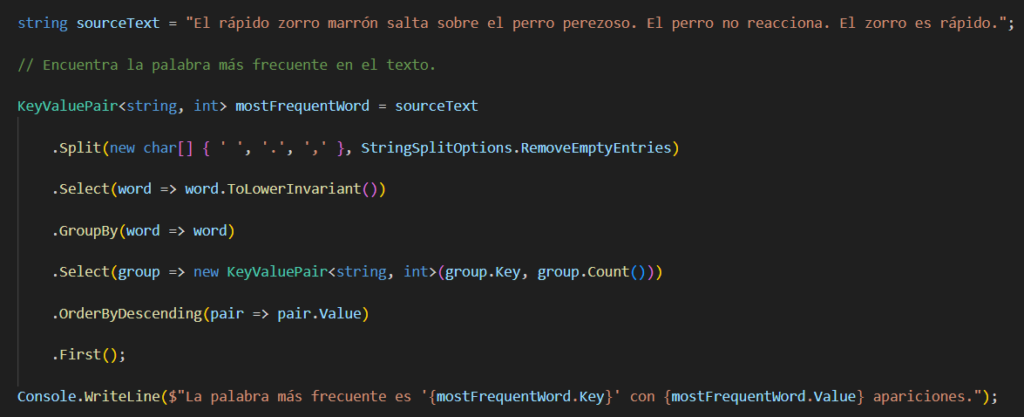
Se han incluido dos nuevos métodos:
- CountBy: que permite calcular la frecuencia de cada clave.
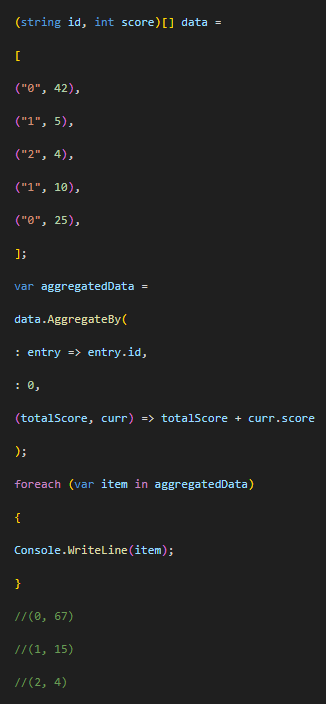
- AggregateBy: permite agrupar datos basados en una clave específica y aplicar una operación de agregación (como una suma) sobre los valores asociados a esa clave.
Ejemplo:
Colecciones
En las colecciones PriorityQueue<TElement,TPriority>, incluye un nuevo método Remove(TElement, TElement, TPriority, IEqualityComparer<TElement>) , que puede usarse para modificar la prioridad de un elemento de la cola.
// Scan the heap for entries matching the current element.
queue.Remove(element, out _, out _);
// Re-insert the entry with the new priority.
queue.Enqueue(element, priority);
Eliminación del Elemento:
- queue.Remove(element, out _, out _) busca y elimina el elemento especificado de la cola de prioridad. Los parámetros out permiten capturar el elemento eliminado y su prioridad anterior, pero en este caso no los usamos (out _, out _).
Reinserción del Elemento con Nueva Prioridad:
- queue.Enqueue(element, priority) inserta el elemento nuevamente en la cola de prioridad, pero con la nueva prioridad especificada.
Criptografía
- CryptographicOperations.HashData(): la API CryptographicOperations.HashData. introducido en .NET 9, permite generar un hash o HMAC a través de una entrada como una captura en la que un algoritmo utilizado viene determinado por HashAlgorithmName. en lugar de tener que llamar a la clase SHA256.HashData o HMACSHA256.HashData dependiendo del tipo de algoritmo que queremos.
- Algoritmo KMAC: .NET 9 proporciona el algoritmo KMAC especificado por NIST SP-800-185. El código de autenticación de mensajes (KMAC) de KECCAK es una función pseudoaleatoria y una función hash con clave basada en KECCAK.KMAC está disponible en Linux con OpenSSL 3.0 o posterior, y en la compilación 26016 o posterior de Windows 11. Puede usar la propiedad estática IsSupported para determinar si la plataforma admite el algoritmo deseado.
Reflexión
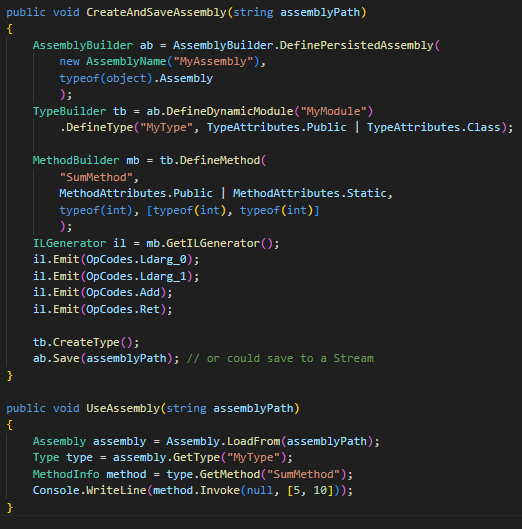
En .NET 9, se introduce la capacidad de guardar ensamblados dinámicamente creados utilizando la nueva API AssemblyBuilder.DefinePersistedAssembly. Esto soluciona una limitación en versiones anteriores de .NET Core y .NET 5-8, donde los ensamblados creados dinámicamente no se podían guardar.
Características Clave:
1. Creación de Ensamblado Persistente:
- API Nueva: AssemblyBuilder.DefinePersistedAssembly.
- Independiente del Entorno de Ejecución: Funciona en cualquier plataforma soportada por .NET 9.
- Sólo Guardar: La implementación actual solo admite la funcionalidad de guardar, no ejecutar.
2.Compatibilidad con Código Existente:
- Los pasos para definir módulos, tipos, métodos, escribir lenguaje intermedio (IL) y otros usos de System.Reflection.Emit permanecen sin cambios.
- Esto significa que el código existente que utiliza System.Reflection.Emit puede seguir siendo utilizado para crear y guardar ensamblados.
3.Uso del Ensamblado Guardado:
- Una vez guardado, el ensamblado puede ser cargado y utilizado como cualquier otro ensamblado .NET.
Rendimiento
La nueva versión de :NET, .NET 9 incluye mejoras en el compilador JIT de 64 bits. Estas mejoras del compilador incluyen:
- Mejor generación de código para bucles.
- Más métodos de inserción para AOT nativo.
- Comprobaciones de tipos más rápidas.
Pruebas unitarias
Ejecución de pruebas en paralelo
En .NET 9, dotnet test está totalmente integrado con MSBuild. Dado que MSBuild admite la compilación en paralelo, puede ejecutar pruebas para el mismo proyecto en diferentes marcos de destino en paralelo. De forma predeterminada, MSBuild limita el número de procesos paralelos al número de procesadores del equipo. También puede establecer su propio límite mediante el modificador -maxcpucount. Si desea no participar en el paralelismo, establezca la propiedad TestTfmsInParallel de MSBuild en false.
Pantalla de prueba del registrador de terminal
Los informes de resultados de pruebas para dotnet test ahora se admiten directamente en el registrador de terminales de MSBuild. Obtendrá informes de pruebas más completos tanto mientras se ejecutan pruebas (muestra el nombre de la prueba en ejecución) y después de que se completen las pruebas (los errores de prueba se representan de una manera mejor).
Conclusión
C# 13 y .NET 9 traen consigo una serie de mejoras y nuevas características que prometen mejorar la eficiencia, la claridad y la funcionalidad de los desarrolladores. Con la introducción de innovaciones como la capacidad de usar el operador de índice implícito “from the end” en inicializadores de objetos, la optimización de la resolución de sobrecargas y la incorporación de nuevas secuencias de escape, C# 13 facilita un desarrollo más intuitivo y menos propenso a errores.
Por otro lado, .NET 9 no se queda atrás, ofreciendo mejoras significativas en áreas críticas como la serialización, LINQ, colecciones, criptografía, reflexión y rendimiento. La nueva API `CryptographicOperations.HashData` simplifica la generación de hashes y HMACs, mientras que las mejoras en la biblioteca `System.Text.Json` y en el compilador JIT de 64 bits demuestran un claro enfoque en el rendimiento y la eficiencia.
Además, la integración completa de `dotnet test` con MSBuild para ejecutar pruebas en paralelo, junto con un mejor soporte para los informes de resultados de pruebas en el registrador de terminales, subraya el compromiso de .NET 9 con la mejora continua de las herramientas de desarrollo y pruebas.
En resumen, estas actualizaciones no solo mejoran la experiencia de desarrollo, sino que también preparan a los desarrolladores para enfrentar los desafíos modernos con herramientas más robustas y flexibles. Con C# 13 y .NET 9, Microsoft sigue demostrando su dedicación a la innovación y la excelencia en el desarrollo de software.
Referencias
1. Novedades de .NET 9, https://learn.microsoft.com/es-es/dotnet/core/whats-new/dotnet-9/overview, accedido el 30 de julio de 2024.
2. Novedades de C# 13, https://learn.microsoft.com/es-es/dotnet/csharp/whats-new/csharp-13, 20 julio 2024.
3. .NET 9 Preview 2 – Release Notes, https://github.com/dotnet/core/tree/main/release-notes/9.0/preview/preview2, 20 julio 2024.
4. This document lists known breaking changes in Roslyn after .NET 8 all the way to .NET 9, https://learn.microsoft.com/es-es/dotnet/csharp/whats-new/breaking-changes/compiler%20breaking%20changes%20-%20dotnet%209, 20 julio 2024.